数据库
oracle数据库自启动和关闭脚本调用
数据库灾备恢复小结
DMS使用文档
Oracle12C安装文档_李光升
Centos配置yum源的操作步骤-李光升
CCS数据库突然卡顿问题解决-徐铭
Centos 7.9静默安装oracle 12cR2详细步骤
mysql5.7数据库sql语句数据类型隐式转换的反逻辑BUG
RDS MySQL临时文件导致实例磁盘空间满且出现“锁定中”状态
关于Mysql引擎Myisam和InnoDB的使用
MySQL查询语句中in和exists区别详解-知识点
Mysql 的存储过程中 WITH AS 的语法和使用
Mysql 性能调优-详解
oracle数据库DG搭建
SUSE linux 配置时钟同步服务NTP/Chrony
oracle数据库实例开启操作文档
oracle数据库实例关闭操作文档
oracle数据库DBS备份配置文档v2
ALiYun ECS CENTOS数据上传到OSS操作手册
Oracle - LOGMINER配置方法
oracle sysaux表空间爆满清理unified auditing数据
sysaux表空间爆满WRI$_ADV_OBJECTS占用严重
SAP权限对象
SYSAUX表空间WRI$\_ADV\_OBJECTS表过大清理V2
oracle:表访问方式
ORA性能诊断调优
数据字典(DICT)和性能事件类型(EVENT)
日志挖掘LogMiner
RMAN sql_id “0az7czjdw8z7j” 执行计划异常
Oracle11g Active Data Guard搭建、管理
ORACLE LOGMINER配置v2
oracle日志组调整
ECS linux服务器挂载nas磁盘失败
oracle数据库修改字符集
datapump数据泵导入导出
OA系统数据库ADG架构搭建
IPS数据库SQL执行异常:ORA-00600
oracle 12c 创建PDB
oracle数据库监听异常
lvm:阿里云磁盘扩容,lvm扩容
Redis基本操作
SAP S4 CLIENT COPY(800->400)
日常数据库操作
PGSQL操作
# ORA-00054: resource busy问题处理
OA数据库服务器故障分析报告
CCS数据库生产数据库(北京中心)覆盖到VER环境数据库(乌兰察布):使用nonpdb to pdb迁移方式
WINDOWS环境Django框架连接MySQL数据库配置
Django开发学习实战
什么是向量嵌入?
OA数据库服务器内次异常增长问题分析
基于AI的自动化服务器管理
AI技术发展趋势及其在农牧食品行业的创新应用
IPS数据库日志表数据归档&表分区
国产编程模型GLM-4.6海外爆火:性能媲美ClaudeSonnet,性价比优势显著
免费开源的零代码平台 / 无代码平台,敲敲云 v2.2.0 版本
数据库原理与应用
AI发展近况分析
ORACLE ADG环境下解除ADG关系并激活备库为独立数据库
麦肯锡重磅报告:关于未来的生存指南,当57%的工作被自动化,我们如何与AI结成利益共同体
【Oracle】Cursor(游标)
ORACLE数据库在曾经的备库(路径一致)进行不完全恢复
获取执行计划的6种方法
人工智能行业的发展已进入“系统竞争”时代
2026年AI与机器人发展趋势
事务未提交导致行锁等待问题处理
MongoDB日常操作命令
2026年人工智能前沿技术趋势与应用落地分析
Doris开发
人工智能在数据库运维工作中的应用趋势与落地场景研究
帆软报表开发学习
AI 助手在 Oracle DBA 工作中的辅助能力研究报告
AI原生数据库发展趋势白皮书
OpenClaw数据库管理应用实践
Apache Doris 简介
本文档使用「觅思文档专业版」发布
-
+
首页
Doris开发
# Doris开发 1. DDL 1. 在 Doris 中,建表时必须选择**数据模型**,这决定了数据的存储、更新和聚合方式。 2. **三种模型:** | 模型 | 描述 | 对应 MySQL 场景 | | --- | --- | --- | | Duplicate (明细模型) | 存什么样查什么样,不做聚合。 | 普通的日志表、流水表。 | | Unique (主键模型) | Key 相同则覆盖(Upsert)。 | 业务库同步过来的有主键的表。 | | Aggregate (聚合模型) | Key 相同则按 Value 进行聚合(Sum/Max/Min)。 | 预计算报表、指标统计。 | * 1. **示例1**:CREATE TABLE \-DUPLICATE模型 (类似 MySQL,需指定分桶) 1. CREATE TABLE user\_log ( user\_id BIGINT, visit\_date DATE, city VARCHAR(20\), age INT) 2. DUPLICATE KEY(user\_id, visit\_date) \-\- DUPLICATE指定模型类型。KEY()指定user\_id,visit\_date为排序键,类似索引 3. DISTRIBUTED BY HASH(user\_id) BUCKETS 10 4. PROPERTIES ("replication\_num" \= "1"); 2. **示例2**:CREATE TABLE\- UNIQUE模型 (实现 MySQL 的 Replace/Update 语义) 1. CREATE TABLE user\_info ( user\_id BIGINT, username VARCHAR(50\), last\_login DATETIME) 2. UNIQUE KEY(user\_id)\-\-\-\- UNIQUE指定模型类型。KEY()指定user\_id为排序键,类似索引 3. DISTRIBUTED BY HASH(user\_id) BUCKETS 10 4. PROPERTIES ("replication\_num" \= "3");  * + 1. 执行报错, 2. 报错原因分析:架构分析  * + - 1. fe:frontend 前端节点:SQL解析 2. ms:meta service 元数据服务:存放元数据(如库表结构、分区信息等) 3. be:backend后端节点:数据存储(数据存放到be/storage),PROPERTIES ("replication\_num" \= "3")设置数据副本数,如果不显式设置,Doris 会使用默认副本数(通常为 3,来源于FE 配置 default\_replication\_num)。但在单 BE 环境下,默认值 3 会导致建表失败,因为无法满足副本放置要求。如下图,执行报错。示例2报错即为该原因导致。  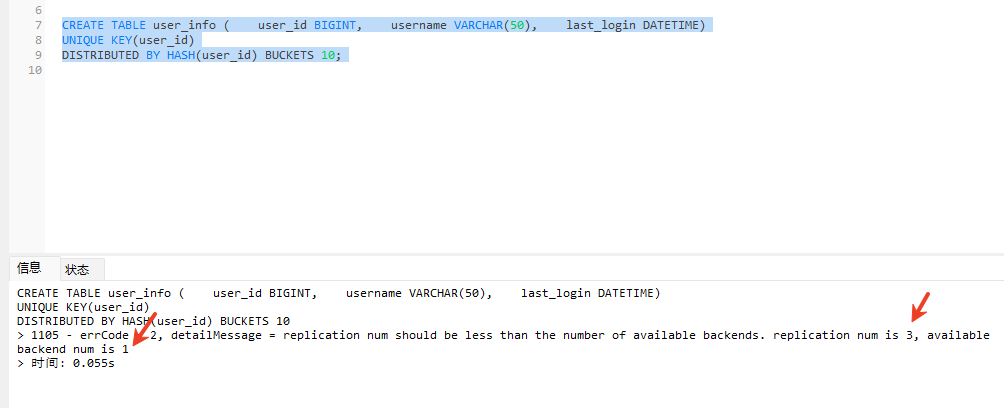 * + 1. 调整数据副本数为1: 2. CREATE TABLE user\_info ( user\_id BIGINT, username VARCHAR(50\), last\_login DATETIME) 3. UNIQUE KEY(user\_id)\-\-\-\- UNIQUE指定模型类型。KEY()指定user\_id为排序键,类似索引 4. DISTRIBUTED BY HASH(user\_id) BUCKETS 10 5. PROPERTIES ("replication\_num" \= "1"); 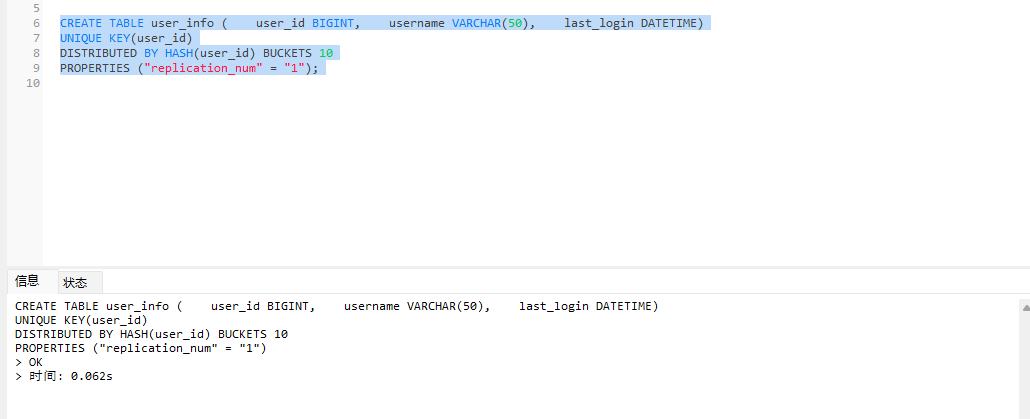 * + 1. PROPERTIES ("replication\_num" \= "1")数据副本数显示设置为1后执行成功。 1. **示例3**:CREATE TABLE \- AGGREGATE模型 (实现 MySQL 的 GROUP BY分组的SUM, REPLACE, MAX, MIN聚合函数语义) 1. CREATE TABLE user\_stats ( 2. user\_id BIGINT, 3. visit\_date DATE, 4. city VARCHAR(20\), \-\- 以上是 Key (维度) 5. visit\_count BIGINT SUM DEFAULT "0", \-\- 自动求和 6. last\_visit\_time DATETIME REPLACE DEFAULT CURRENT\_TIMESTAMP, \-\- 记录最后一次出现的值 7. max\_stay\_duration INT MAX DEFAULT "0", \-\- 记录最大值 8. min\_stay\_duration INT MIN DEFAULT "99999" \-\- 记录最小值 9. ) 10. AGGREGATE KEY(user\_id, visit\_date, city) \-\-AGGREGATE定义模型类型,KEY 定义哪些列是维度 11. DISTRIBUTED BY HASH(user\_id) BUCKETS 5 12. PROPERTIES ("replication\_num" \= "1");  * 1. **示例4**:ALTER TABLE \- 增加字段 1. ALTER TABLE user\_log ADD COLUMN new\_col INT; 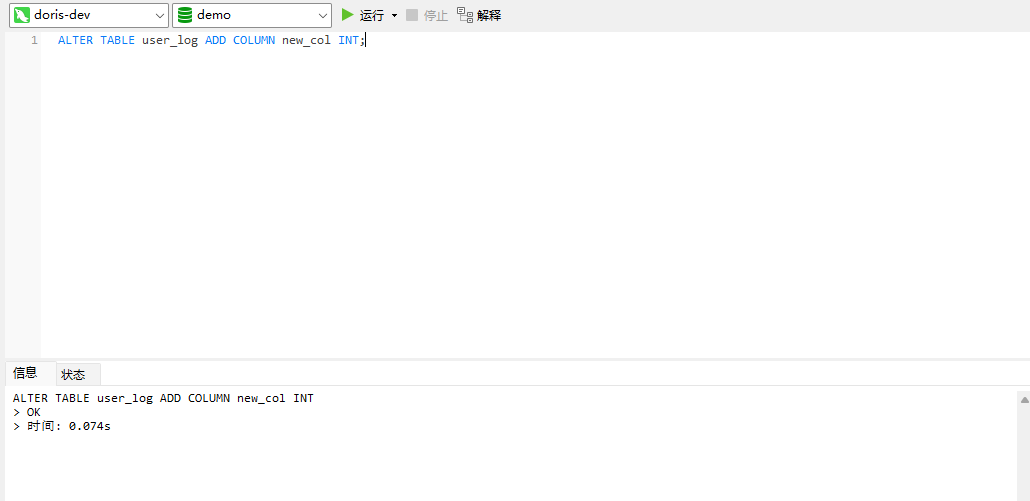 * 1. **示例5**:ALTER TABLE \- 删除字段 1. ALTER TABLE user\_log DROP COLUMN new\_col; 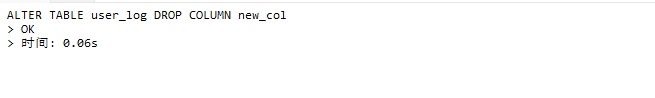 * 1. **示例6**:ALTER TABLE \- 修改表属性 1. 修改副本数 (Replication Num) 2. ALTER TABLE test\_db.user\_stats SET ("replication\_num" \= "3");  * + 1. 修改表注释 2. ALTER TABLE test\_db.user\_stats MODIFY COMMENT "用户访问统计报表";  * 1. **示例7**:ALTER TABLE \- 修改表字段 1. 修改字段类型或长度 2. ALTER TABLE user\_stats 3. MODIFY COLUMN city VARCHAR(50\);  * + 1. 调整字段顺序 (Reorder Columns) 2. ALTER TABLE user\_stats 3. ORDER BY (user\_id, city, visit\_date, visit\_count, last\_visit\_time, max\_stay\_duration, min\_stay\_duration); 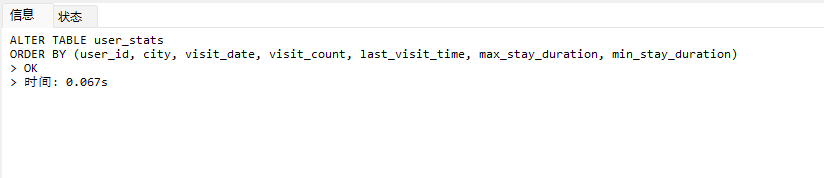 * + 1. select \* from user\_stats 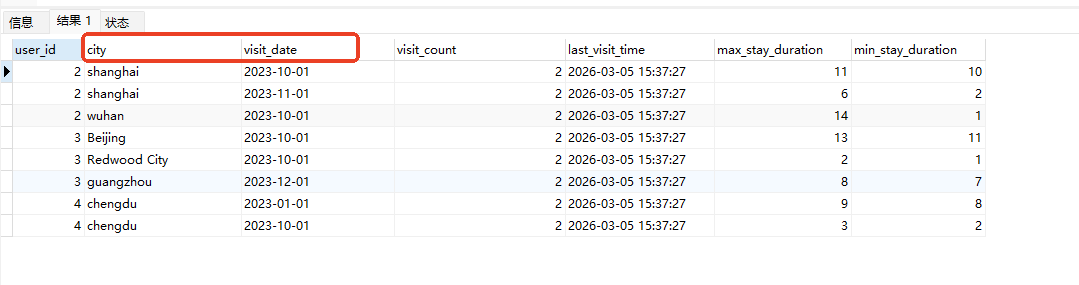 * + 1. ALTER TABLE user\_stats 2. ORDER BY (user\_id, visit\_date,city, visit\_count, last\_visit\_time, max\_stay\_duration, min\_stay\_duration); 3. select \* from user\_stats 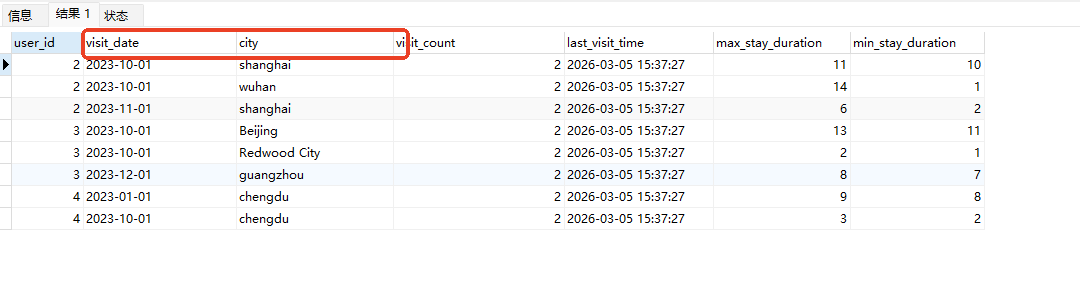 * 1. TIPS 1. **分桶 (Bucketing)**:Doris 强制要求 DISTRIBUTED BY,这决定了数据如何分布在 BE 节点上。 2. **排序键 (Short Key Index)**:DUPLICATE/UNIQUE/AGGREGATE KEY 里的列不仅是逻辑定义,还是物理存储的排序依据,查询时前缀过滤非常快,类似索引。 3. **数据副本数(replication num)**:PROPERTIES ("replication\_num" \= "3")指定数据副本数,以确定表的分区(tablet)在不同的be节点的副本数,默认为3。多个 BE 可以同时响应查询请求以提升并发能力。 4. **Aggregate模型**:Key 列必须在 Value 列之前。 5. **建表属性(如分桶,数据副本数等)**:这些属性作用于分区,即分区创建之后,分区就会有自己的属性,修改表属性只对未来创建的分区生效,对已经创建好的分区不生效。 1. DML 1. Doris 采用类似 **LSM\-Tree(Log\-Structured Merge\-Tree)** 的存储结构。当不断执行 INSERT、UPDATE、DELETE 或批量导入时,数据不是直接覆盖旧文件,而是**增量写入新文件**( Doris 称 **Rowset**)。这样做的优点是写入速度快(顺序写),但缺点是**小文件过多,空间占用大。** 2. **Compaction** 是由 BE 节点的后台线程自动执行的核心的**后台数据合并机制**。 3. Doris 的 Compaction 分为两种主要类型,协同工作: | 类型 | 触发时机 | 合并范围 | 目的 | | --- | --- | --- | --- | | Cumulative Compaction | 频繁触发 | 合并最近生成的多个小文件 | 快速减少小文件数量,防止积压 | | Base Compaction | 周期触发 | 将 Cumulative 合并后的文件与历史基表文件合并 | 彻底消除冗余,形成稳定的大文件 | * 1. **示例1**:INSERT 插入操作(DUPLICATE模型) 1. INSERT INTO user\_log VALUES 2. (1, '2023\-10\-01', 'Beijing', 20\), 3. (2, '2023\-10\-01', 'Shanghai', 25\), 4. (3, '2023\-10\-01', 'shenzhen', 21\), 5. (4, '2023\-10\-01', 'guangzhou', 22\), 6. (5, '2023\-10\-01', 'chengdu', 23\), 7. (6, '2023\-10\-01', 'hangzhou', 24\), 8. (7, '2023\-10\-01', 'chongqin', 25\), 9. (7, '2023\-10\-01', 'wuhan', 26\), 10. (5, '2023\-10\-01', 'chengdu', 27\), 11. (3, '2023\-10\-01', 'Shanghai', 29\); 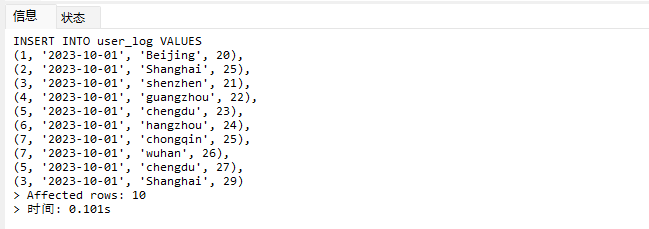 * + 1. select \* from user\_log 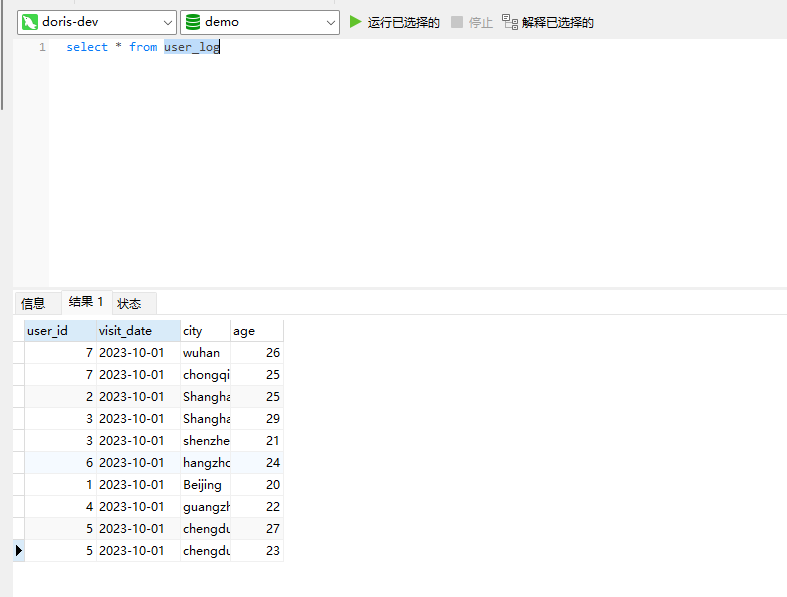 * 1. **示例2**:INSERT 插入操作(UNIQUE模型) 1. insert into user\_info VALUES 2. (1,'wanger',CURRENT\_DATE), 3. (2,'zhangsan',CURRENT\_DATE), 4. (3,'lisi',CURRENT\_DATE), 5. (4,'wangwu',CURRENT\_DATE), 6. (5,'zhouliu',CURRENT\_DATE), 7. (6,'wuqi',CURRENT\_DATE), 8. (1,'xuda',CURRENT\_DATE), 9. (2,'wangxiaoer',CURRENT\_DATE), 10. (3,'lijiu',CURRENT\_DATE); 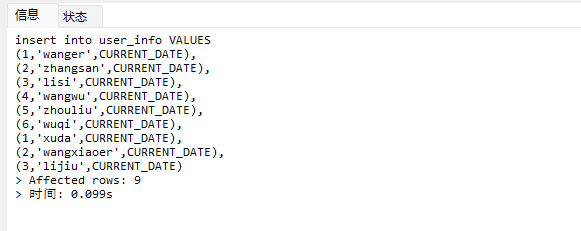 * + 1. select \* from user\_info 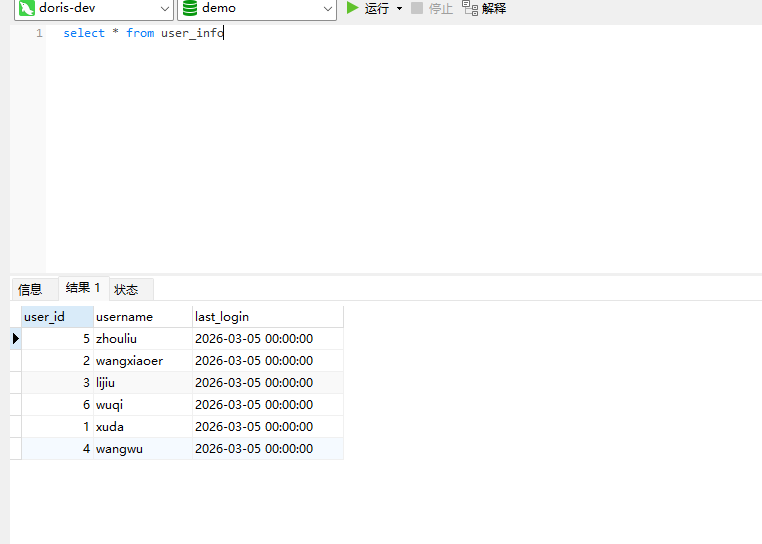 * + 1. user\_info表主键为1,2,3 的username前面插入的值'wanger','zhangsan','lisi'分别被后面插入语句值覆盖为'xuda','wangxiaoer','lijiu' 1. **示例3**:INSERT 插入操作(AGGREGATE模型) 1. INSERT INTO user\_stats VALUES 2. (1, '2023\-10\-01', 'Beijing', 1,NOW(),5,5\), 3. (2, '2023\-11\-01', 'shanghai', 1,NOW(),6,6\), 4. (3, '2023\-12\-01', 'guangzhou', 1,NOW(),7,7\), 5. (4, '2023\-01\-01', 'chengdu', 1,NOW(),8,8\), 6. (1, '2023\-10\-01', 'Beijing', 1,NOW(),9,9\), 7. (2, '2023\-10\-01', 'wuhan', 1,NOW(),1,1\), 8. (3, '2023\-10\-01', 'Redwood City', 1,NOW(),2,2\), 9. (4, '2023\-10\-01', 'chengdu', 1,NOW(),3,3\), 10. (1, '2023\-10\-01', 'San Jose', 1,NOW(),4,4\), 11. (2, '2023\-10\-01', 'shanghai', 1,NOW(),11,11\), 12. (3, '2023\-10\-01', 'Beijing', 1,NOW(),11,11\); 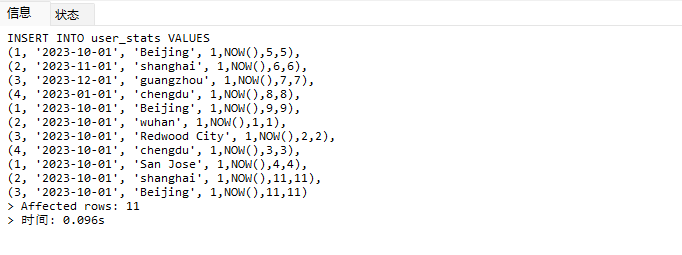 * + 1. select \* from user\_stats 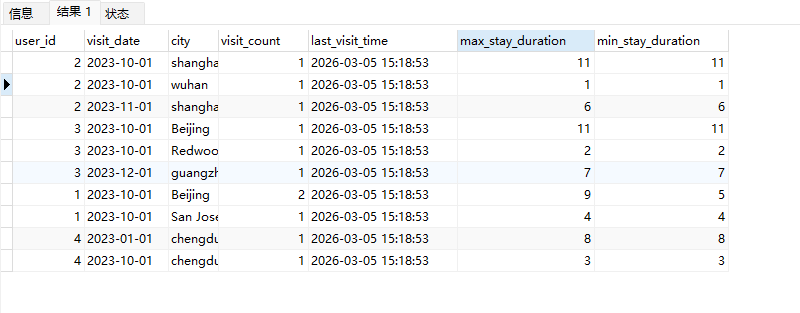 * + 1. 以上,只有(1, '2023\-10\-01', 'Beijing', 1,NOW(),5,5\),(1, '2023\-10\-01', 'Beijing', 1,NOW(),9,9\)两条发生聚合生成条目:(1 2023\-10\-01 Beijing 2 2026\-03\-05 15:18:53 9 5)。即user\_id,visit\_date,city三者值皆相同发生聚合(对比GROUP BY user\_id,visit\_date,city) 2. 再插入,尝试多次发生聚合 3. INSERT INTO user\_stats VALUES 4. (1, '2023\-10\-01', 'Beijing', 1,NOW(),1,1\), 5. (2, '2023\-11\-01', 'shanghai', 1,NOW(),2,2\), 6. (3, '2023\-12\-01', 'guangzhou', 1,NOW(),8,8\), 7. (4, '2023\-01\-01', 'chengdu', 1,NOW(),9,9\), 8. (1, '2023\-10\-01', 'Beijing', 1,NOW(),19,19\), 9. (2, '2023\-10\-01', 'wuhan', 1,NOW(),14,14\), 10. (3, '2023\-10\-01', 'Redwood City', 1,NOW(),1,1\), 11. (4, '2023\-10\-01', 'chengdu', 1,NOW(),2,2\), 12. (1, '2023\-10\-01', 'San Jose', 1,NOW(),5,5\), 13. (2, '2023\-10\-01', 'shanghai', 1,NOW(),10,10\), 14. (3, '2023\-10\-01', 'Beijing', 1,NOW(),13,13\); 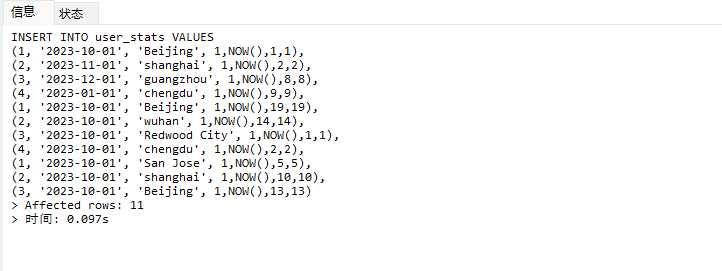 * + 1. select \* from user\_stats 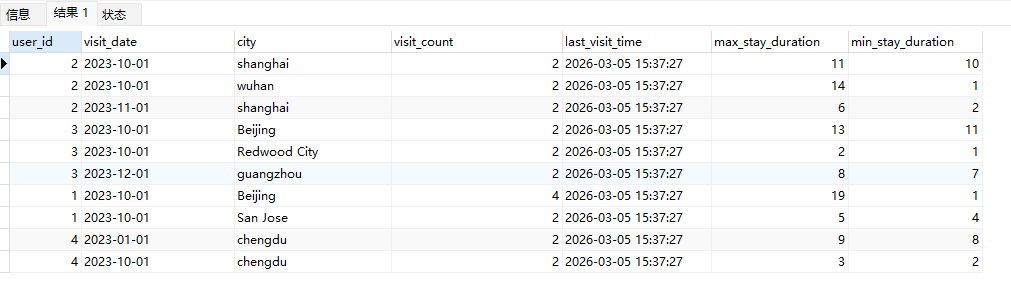 * + 1. 多次发生聚合 1. **示例4**:更新操作 UPDATE(必须基于 Unique 模型) 1. Doris 的 UPDATE 实际上是先标记删除旧行,再插入新行。 2. SELECT \* FROM user\_info; \-\-\-\-user\_info是UNIQUE模型 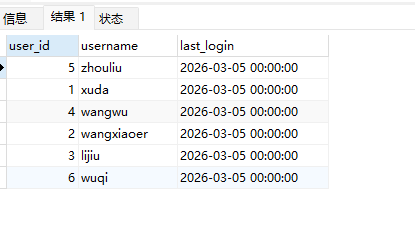 * + 1. UPDATE user\_info SET username\='老徐' WHERE user\_id \=1; 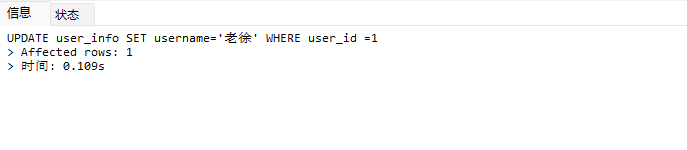 * + 1. SELECT \* FROM user\_info; 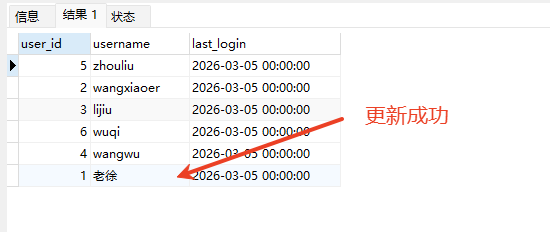 * + 1. SELECT \* FROM user\_log; \-\-\-\-\-user\_log是DUPLICATE模型 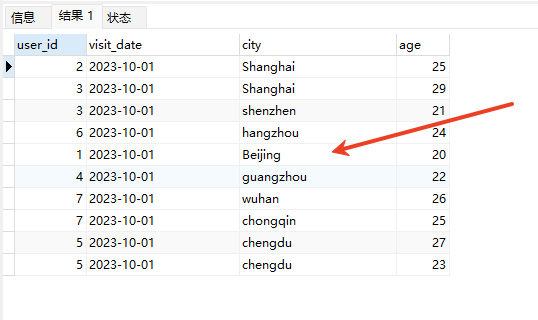 * + 1. UPDATE user\_log SET city\='chengdu' WHERE user\_id \=1; 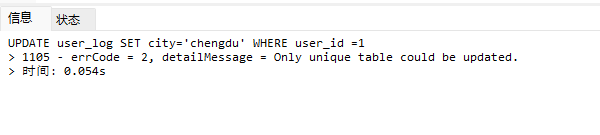 * + 1. 执行报错,提示:Only unique table could be updated. 2. SELECT \* FROM user\_stats; \-\-\-\-\-user\_stats是AGGREGATE模型 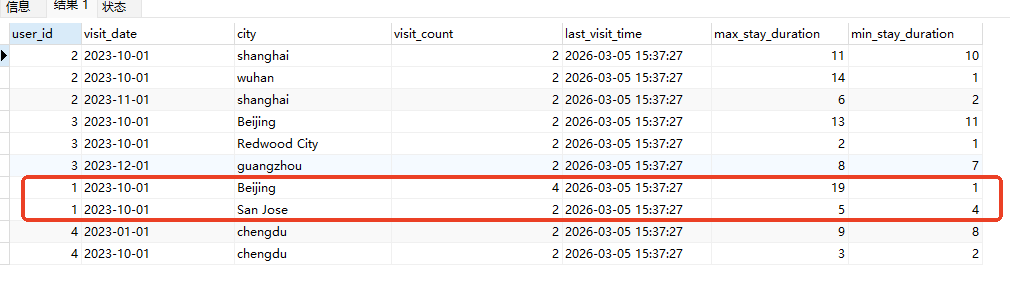 * + 1. UPDATE user\_stats SET city\='Beijing' WHERE user\_id \=1; 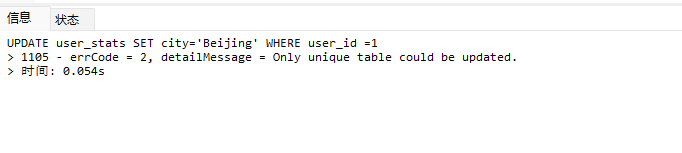 * + 1. 执行报错,提示:Only unique table could be updated. 2. 在 AGGREGATE/UNIQUE 模型中,**通常不需要使用 UPDATE 语句**。 3. 如果你想更新 last\_visit\_time,你只需要 INSERT 一条 Key 相同的新数据,Value 列会自动根据 REPLACE 函数覆盖旧值。 1. **示例5**:删除操作 DELETE 1. Doris 的 DELETE 提交后,数据并不会立即从磁盘消失,而是被打上标记,在后台 Compaction 时物理删除。 2. 如果你要删除整个分区,使用 ALTER TABLE t DROP PARTITION p1,这比 DELETE 快得多,且不消耗 CPU。 3. **UNIQUE模型** 4. SELECT \* FROM user\_info; 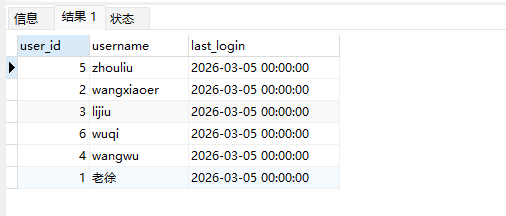 * + 1. DELETE FROM user\_info WHERE user\_id \= 1; 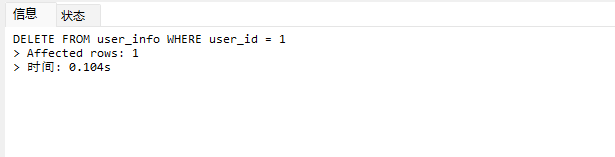 * + 1. SELECT \* FROM user\_info; 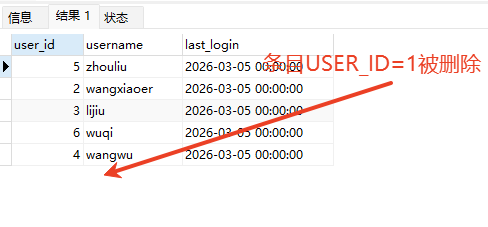 * + 1. **DUPLICATE模型** 2. SELECT \* FROM user\_log; 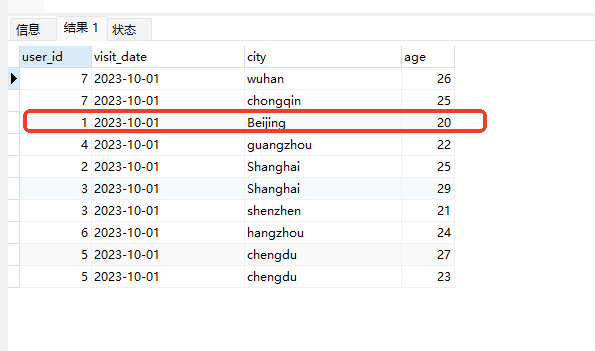 * + 1. DELETE FROM user\_log WHERE user\_id \= 1; 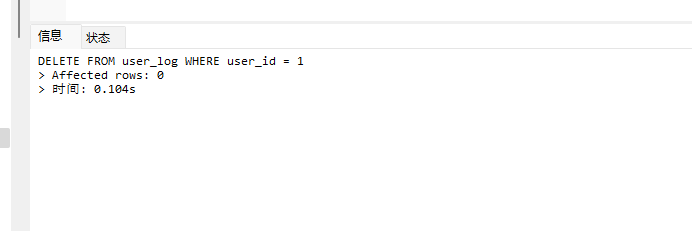 * + 1. SELECT \* FROM user\_log; 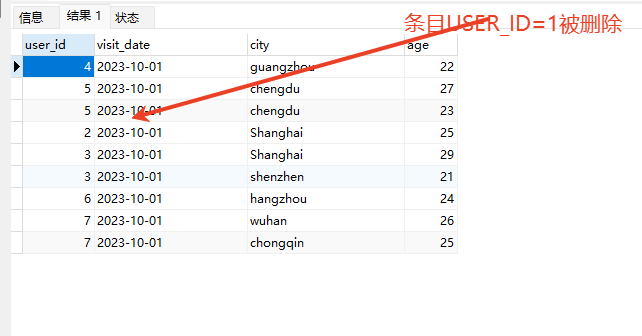 * + 1. **APPREGATE模型** 2. SELECT \* FROM user\_stats; 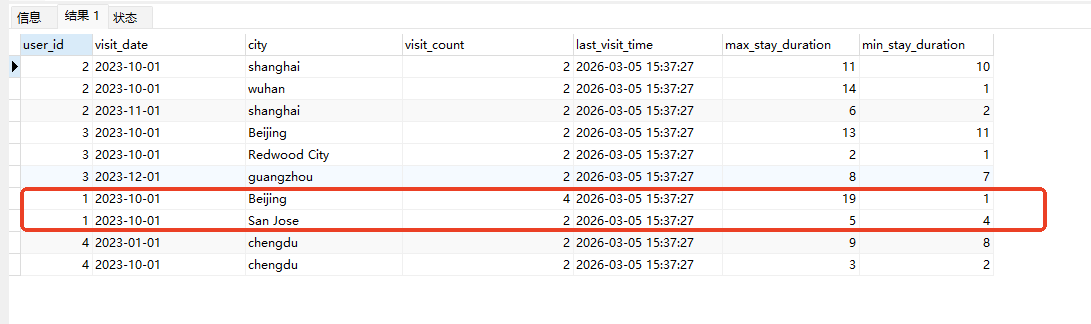 * + 1. DELETE FROM user\_stats WHERE user\_id \= 1;  * + 1. SELECT \* FROM user\_stats; 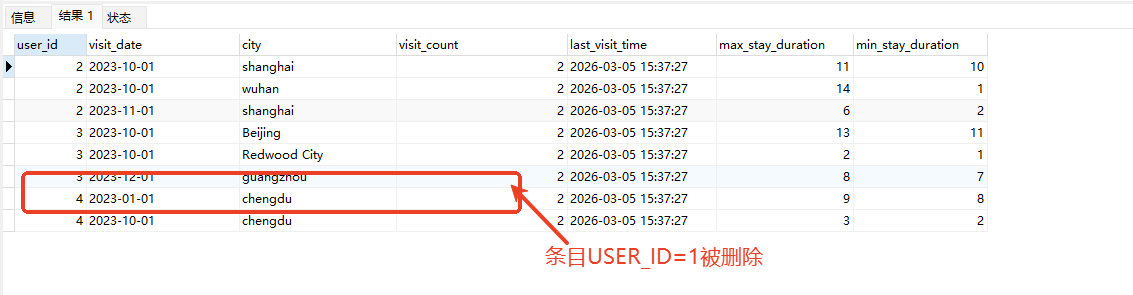 * + 1. 实际上,在APPREGATE模型中,如果你执行 DELETE FROM user\_stats WHERE user\_id \= 1,Doris 会生成一条标记记录,在查询时过滤掉该 Key 的所有聚合结果。 1. **示例6**:查询操作 SELECT(Doris的最强技) 1. Doris 的 SELECT 语法与 MySQL 几乎一致,但处理大量数据的能力却强太多太多太多太多... 2. SELECT \* FROM user\_log; 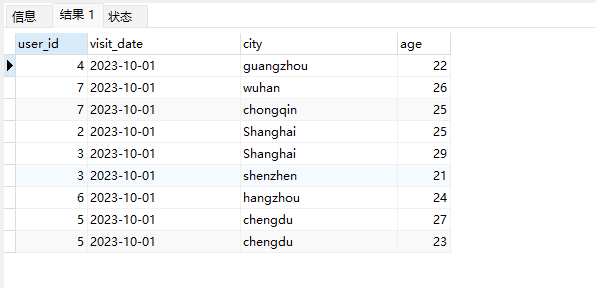 * + 1. SELECT 2. city, 3. COUNT(DISTINCT user\_id), 4. SUM(age) 5. FROM user\_log 6. GROUP BY city 7. ORDER BY 2 DESC; 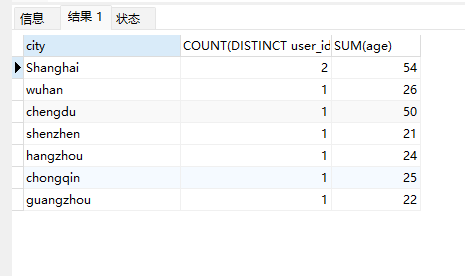
徐铭
2026年3月31日 13:55
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期