基础架构部文档
基础架构部文件格式标准参考
技术文档
mr_doc 接入ucenter 认证登录
loki日志收集
https证书与ssl/tls 加密
FTP 主动模式和被动模式的区别
Hadoop-windows10安装部署Hadoop2.7.3
JKS和PFX证书文件格式相互转换方法
KVM 基础操作
k8s nginx ingress日志收集到ELK并分析
Django基础
clash http代理 socks代理服务器搭建 配置
Ubuntu 22.04 安装 FFmpeg v7.0
ORM
AI MCP 介绍
Django 模板
ZooKeeper命令行(zkCli)的常用操作
Office正版化项目的个人体验和心得
重置jenkins构建历史
K8S实施方案
k8s的yaml文件语法
Docker的优势与虚拟机的区别
问题处理文档
HR推送数据问题处理报
Nginx从入门到放弃01-nginx基础安装
Nginx从入门到放弃02-Nginx基本命令和新建WEB站点
Nginx从入门到放弃03-Nginx调优
Nginx从入门到放弃04-Nginx的N种特别实用示例
JMeter教程
01-mariadb编译安装
02-mariadb二进制安装
Docker修改默认的存储路径
01-influxdb2时序数据库简介及安装
02-influxdb2时序数据库核心概念
03-influxdb2时序数据库flux查询语言
04-influxdb2--Python客户端influxdb-client
05-Spring boot 集成influxdb2
06-influxdb2其他知识
OA添加waf后相关问题的解决过程
排除java应用cpu使用率过高
exsi迁移文档
视频测试
阿里云产品试题
超融合服务器和传统服务器的区别
Serv-U问题集锦
文件夹共享操作手册
磁盘脱机处理方案
Office内存或磁盘空间不足处理方法
Cmd中ping不是内部或外部命令的解决方法
ELK 搭建文档
限制用户的远程桌面会话数量
Docker快速安装rocketmq、redis、zookeeper
超融合建设方案
git 入门
HR系统写入ES数据报错403
ELK搭建文档
KVM 安装和基础使用文档
helm 安装 rancher
访问共享提示禁用当前用户解决方法
K8S StorageClass搭建
KVM 扩展磁盘
借助sasl构建基于AD用户验证的SVN服务器
fastdfs编译安装并迁移数据
关闭系统保护的必要性
SCF 前置机部署
阿里云OSS学习文档
阿里云学习文档-VPC
(k8s踩坑)namespace无法删除
rancher-helm安装
zookeeper集群安装
批量替换K8s secrets 中某个特定域名的tls证书
kibana 批量创建索引模式
centos7 恢复Yum使用
ACP云计算部分知识点总结
Loki 日志系统搭建文档
自动更新k8s集群中所有名称空间中特定证书
AI分享
(AI)函数调用与MCP调用的区别
安装戴尔DELL Optilex 7040 USB驱动时提示无法定位程序输入点 kernel32\.dll
新华三服务器EXSI 显卡直通
conda
双流本地k8s搭建
通义灵码介绍
ELK高亮显示字段过大的问题
LInux常用工具
Ollama部署本地deepseek
人工智能如何重塑ACG宇宙
网络基础协议
远程桌面忽略本地机的文本缩放设置
ComfyUI :构建可视化 Stable Diffusion 工作流
Clawdbot介绍
Dify:开启AI应用开发的“乐高时代”
Kubernetes 证书过期处理
Openclaw安装
Openclaw介绍
zk高可用集群安装
AI代码审计
IaC学习
本文档使用「觅思文档专业版」发布
-
+
首页
LInux常用工具
# vim 编辑器 命令行模式 进入vim 默认模式 命令行快捷键 $ 光标移动到当前行的末尾 0 光标移动到当前行的开始 dd 删除光标所在的那一行 ndd n是数字,删除光标所在行向下的n行 u 撤销上一步操作 yy 复制光标所在的哪一行 nyy 复制光标所在行向下的n行 p 粘贴复制内容,复制在光标光标所在行下面 np 进行n次复制 P 粘贴复制内容,复制在光标光标所在行上面 把yy 换成dd 就变成了剪切操作 gg 第一行的行首 G 最后一行的行首 ng 跳转到文件的某一行 ctrl+v 可视块 批量去注释: Ctrl + v 进入可视块 光标选中要删除的列 按 dd 删除 批量加注释: Ctrl + v 进入可视块 光标选中要加注释的列,shift + i 进入编辑模式 编辑第一行后按两次 esc即可加上 输入模式 命令行模式通过 a i o O 按键 进入 通过ecs键退出到命令行模式 末行模式 命令行通过 : 键进入 通过ecs键退出到命令行模式 wq 保存退出 x 保存退出 q! 强制退出,不保存 wq! 强制保存退出(在没有权限的时候可以使用,前提是有root权限) % s/egon/EGON/g 替换所有行中的所有的egon % 所有行 g 替换一行中所有匹配的 1,3 s/egon/EGON/g 替换1-3行的所有egon 3,$ s/egon/EGON/g 替换3-末尾中的所有egon % s/^egon/EGON/g 替换所有行中 开头的egon % s/egon$/EGON/g 替换所有行中 末尾的egon % s/egon/MMM/gi 不区分大小写,替换所有行中的egon s 可以使用正则表达式匹配 3,5 w /root/aa.txt 把3-5行复制到root目录下的aa.txt文件 r /etc/host 把/etc/host 文件内容读取到当前文件 #临时修改 set nu 设置显示行号 set nonu 设置关闭显示行号 set ic 全局不区分大小写 set ai 自动缩进 #永久修改 在配置文件中增加 /etc/vimrc vimdiff a.txt b.txt 对比两个文件的差异 可以编辑 默认是在左边文件编辑 按ctrl + w + w 可以切换到右边文件 编辑 diff a.txt b.txt diff -u a.txt b.txt > patch.diff 用b.txt为准 用b.txt 制作的补丁 覆盖a.txt patch a.txt patch.diff vim -o a.txt b.txt 可以连续编辑两个文件 上下分页, ctrl + w + w 来回切换 vim -O a.txt b.txt 同上 但是 是左右分页 vim 打开文件会创建一个交换文件 .a.txt.swap 异常退出后 这个文件会保留 vim -r a.txt 可以通过.swap文件恢复上次修改内容 # sed 什么是sed? sed -> 流式编辑器 sed 选项 '规则' a.txt sed 内存空间 有模式空间和保持空间 一般读取一行到模式空间,然后规则处理 ,打印到屏幕 sed 对比 vim 1.sed可以把处理文件的规则事先写好,然后用同一套规则编辑多个文件 而vim 只能一个一个编辑 2.sed 处理文件,一次只处理一行,即同一时间内存中只有文件的一行的内容,无论文件多大,都不会对内存造成过大的压力 --> 用于处理大文件 如何用sed sed 选项 '规则' 文件 选项: -i 改变输出流向 从屏幕改到源文件 -n 取消默认输出,不会打印到屏幕 规则: 定位+命令 定位 没有定位代表匹配所有行 行号定位 sed '1p' a.txt sed '1,3p' a.txt sed '3p;5p' a.txt 正则定位 sed '/egon$/d' a.txt 命令: d 删除匹配行 p 打印匹配行 s///gi 替换 sed '定位s///' 文件 sed '1,3s/egon/EGON/' a.txt 将1-3行的行首egon替换为EGON sed 's/egon/EGON/g' a.txt 将所有行的中的所有egon替换为EGON sed 's/egon/EGON/gi' a.txt 将所有行中的所有egon(不区分大小写) 替换为EGON a 在匹配行之下追加 i 在匹配行之上最加 # awk 主要擅长处理有规律的文本,主要用于做一些格式化处理 awk -F : '{print $1 ,$3}' /etc/passwd awk 选项 '规则' 文件 选项: -F 指定分割符 不指定分隔符 默认分隔符为空格 规则:定位+命令 定位 没有定位代表匹配所有行 行号定位 NR == 1 awk -F: 'NR==3{print$1,$3}' 文件路径 awk -F: 'NR>=3&&NR<=5{print$1.$3}' /etc/passwd 匹配3-5行 awk -F: 'NR<=3||NR>=8{print $1,$3}' /etc/passwd 匹配前三行和八行之后的所有行 正则定位 awk -F : '//{print $1,$2}' 文件路径 awk -F: '/nologin$/{print $1 $2}' 文件路径 awk -F: '$6 ~ /root/{print $0}' /etc/passwd 只在第6列进行正则匹配 awk -F: '$6 !~ /root/{print $0}' /etc/passwd 反选 NR 代表行号 NF 代表被分割为几段 awk -F:'{print $NF}' test.txt 取倒数第一段 awk -F: '{print $(NF-1)}' test.txt 取倒数第二段 命令: {print $n} # grep 擅长过滤 grep 选项 "过滤规则" 文件 选项: -n 显示行号 -i 忽略大小写 --clolor 显示颜色 -l 匹配成功,返回文件名 -r 递归遍历文件夹 -v 取反 grep -rl 'egon' /etc/ 遍历/ect 下面的所有文件,打印出文件中有egon 字符的文件名 过滤规则: 正则表达式 # 文件管理 文件:文件是操作系统提供给用户操作硬盘的一种功能 文件系统:文件系统是操作系统中负责控制硬盘的一个软件 文件系统 ----> 文件 1.文件查找命令 # find -i 忽略大小写 文件名查找 find /etc -name "ifcfg-eth0" 文件大小查找 find /etc -size +3M 查找大于3M的文件 find /etc -size -3M 查找小于3M的文件 find /etc-size +3M -ls 用列表形式打印 find / -maxdepth 5 -a -name '文件名' 指定只查找5层文件夹并且满足文件名的文件 find / -name '文件名' -o -size +3M 满足文件名或者大于3M的文件 -a 并且 可以不加 默认是-a -o 或者 dd if=/dev/zero of=b.txt bs=1024 count=1 input file output file block size 文件有四种时间 最近访问时间 最近移动时间 最近修改时间 创建时间时间 stat a.txt find /home -user egon -group egon find ./ -nouser find ./ -nogroup find /dev -type -f 普通文件 find /dev -type -d 文件夹 find /dev -type -l 链接 f 普通文件 d 目录 l 链接 b 块设备 c 字符设备 s 套接字 p 管道文件 根据inode号找 find / -inum 1011 根据文件权限找 find . -perm 644 -ls 按时间查找(atime ,mtime , ctime) find /etc -mtime +3 #修改时间超过3天的 find /etc -mtime 3 #修改时间等于3天的 find /etc -mtime -3 #修改时间小于3天的 需求 查找没有用户和没有用户组的文件然后是删除 rm 不支持管道 用xargs find /home -nouser -nogroup | xargs rm -rf -I {} find /etc -name 'ifcfg-eth0' | xargs -I {} cp -rf {} /var/tmp find 命令本身是有这样的选项的 find /root/ -maxdepth 1 -name "*.txt" -ok rm -rf {} \; find /root/ -maxdepth 1 -name "*.txt" -exec rm -rf {} \; -ok 有提示 -exec 没有提示 文件上传和下载 下载 # wget wget -O 本地路径 远程包链接地址 #将远程包下载至本地路径 如果wget 提示无法建立ssl连接,则加上选项--no-check-certificate wget --no-check-certificate -O 本地路径 远程包链接地址 curl -o 123.png https://www.xxx.com/1.png yum install lrzsz -y 只有windows可用 rz 本地上传到服务器 sz 服务器下载到本地 while true ; do curl 网络地址; done # 输出与重定向 >覆盖 >> 追加 ifconfig >> a.txt 将ifconfig结果追加到a.txt ifconfig > a.txt 将ifconfig结果覆盖a.txt内容 0 键盘输入 1 标准正确输出 2 标准错误输出 ifconfig ensxxxx 1 > a.txt 2 > b.txt 执行命令将标准正确输出打印到a.txt中并且将错误输出打印到b.txt中 不写默认是1,只会把正确结果输出到文件 要两个结果都输出到一个文件 需要把标准错误重定向到标准输出 两种写法: ifconfig ens33 &> c.txt ifconfig enasfse33 > c.txt 2>&1 输入 < 从文件读取 << 从键盘输入 用键盘输入内容覆盖文件内容 cat > d.txt << EOF 111 222 444 EOF 追加键盘输入内容到文件 cat >> d.txt << EOF 111 222 444 EOF # 字符处理命令 # sort 排序命令 sort 选项 文件名 默认是按照 依次用每行的字符 进行升序排序 (用的ASCII码表进行排序) sort -t ':' -n -k 2 a.txt -t 指定分割符 -n 指定数字大小比较,而不是字符比较 -k 用哪列进行比较 -r 用降序进行排列 # uniq 用于检查及删除文本文件中重复出现的行列,一般与sort命令一起使用 -c 在每列旁边显示改行重复出现的次数。 -d 仅显示重复出现的行列 -u 仅显示出现出一次的行列 # cut cut 命令用来显示行中指定部分,删除文件中指定的字段 -d #指定字段的分割符,默认字段分割符为"TAB" -f #显示指定字段内容 head -5 /etc/passwd |cut -d:-f1 head -5 /etc/passwd |cut -d: -f1-3 head -5 /etc/passwd |cut -d: -f1,3 # tr 替换或删除命令 -d 删除字符 echo "Egon is ok hello new" | tr "Egon" "abcd" abcd is ck hellc dew 一一对应替换 # wc 统计,计算数字 -c 统计文件的Bytes数 -l 统计文件的行数 -w 统计文件中的单词个数,默认以空白字符作为分割符。 # 打包压缩 # tar c 创建 v 显示打包内容 f 指定打包文件名 z 使用gzip压缩 j 使用bzip2进行压缩 打包后压缩 tar -cvf bak.tar /etc/passwd /etc/hosts /etc/hostname gzip bak.tar 两个命令合二为一 tar -cvzf bak.tar.gz /etc/passwd /etc/hosts /etc/hostname 可以用bzip2 压缩 tar -cvf bak.tar /etc/passwd /etc/hosts /etc/hostname bzip2 bak.tar 两个命令合二为一 tar -cvjf bak.tar.bz2 /etc/passwd /etc/hosts /etc/hostname 解包解压 tar -xvf bak.tar.bz2 -C 目标文件夹 tar -xvf bak.tar.gz -C 目标文件夹 -x 会自动识别压缩算法,看是调用gunzip 还是 bunzip2 工具进行解压 # zip 打包压缩 zip bak.zip /etc/passwd /etc/hosts /etc/hostname 解包解压 unzip bak.zip unzip bak.zip -d /aaa tar -cvzf `date "+%Y_%m_%d_%H_%M_%S"`_etc_bak.tar.gz /etc/ # 文件系统 文件是操作系统提供给用户操作硬件的一个功能 也就是说操作系统中肯定有一段代码专门用来提供文件的功能 操作系统 文件系统(属于操作系统的一部分) ---> 提供了文件的概念 硬盘 文件系统是操作系统中负责操作硬盘的一段程序,文件系统提供了文件的概念 # df 查看磁盘空间使用率 df -Th 查看inode使用率 df -i 查看inode+ ls -i 文件 ls -di 文件夹 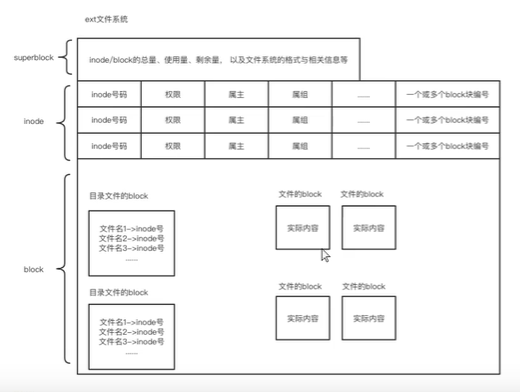 首先,系统找到这个文件名对应的inode号码; 其次,通过inode号码,获取inode信息; 最后,根据inode信息,找到文件数据所在的block,读出数据。 查看文件元数据 stat a.txt ```shell (base) root@yc01:~/yc1# stat a.txt File: a.txt Size: 35 Blocks: 8 IO Block: 4096 regular file Device: fd00h/64768d Inode: 10007923 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2025-10-29 03:06:11.541457948 +0000 Modify: 2025-10-29 02:59:02.223011290 +0000 Change: 2025-10-29 02:59:02.223011290 +0000 Birth: 2025-10-24 06:54:15.223991068 +0000 ``` cat vim 能读取到文件真实内容 都会修改Access时间 Modify 修改内容就会变 Change 修改就会变(内容或者元数据) 但是访问一次后 文件内容会被放在buffer/cache 缓存中 ,后面访问不会变 清理buffer/cache buffer 写缓冲区 cache 读缓冲区 清理之前要执行一下 sync 目的是防止缓冲区的的数据丢失 echo 3 > /proc/sys/vm/drop_caches 动态查看命令 while true ; do df -i ;sheep 0.5 ;clear;done inode 号占满了 1.删除多余小文件 # 硬链接和软链接 # ln 硬链接: ln a.txt b.txt a和b 文件指向的inode号一致,本质他们是一个文件 目录不可创建硬链接,并且硬链接无法跨区 软链接 ln -s a.txt b.txt a b inode不一致 b相当于a的快捷方式。
杨超
2025年10月31日 09:38
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期